


XIII. Utilisation des fichiers▲
Lorsqu'on commence à écrire des applications sérieuses, il apparaît rapidement un
besoin : stocker des informations de façon permanente, que ce soit de façon interne
sans intervention de l'utilisateur, ou de façon externe pour permettre par exemple à
l'utilisateur d'effectuer une sauvegarde des données éditées dans l'application. Le
seul moyen envisageable, mis à part l'utilisation d'une base de données (ce qui
revient finalement au même), est l'utilisation de fichiers.
Les fichiers sont universellement utilisés pour stocker des informations, et leur
utilisation est permise de plusieurs manières par le langage Pascal Objet et Delphi.
Ce chapitre va tout d'abord vous inculquer quelques principes pour l'utilisation des
fichiers, puis les divers moyens d'accès aux fichiers seront étudiés.
XIII-A. Introduction : Différents types de fichiers▲
Cette partie décrit les différents types de fichiers que vous serez amenés à utiliser. La liste présentée ici n'a rien à voir avec une liste de types de fichiers au sens où l'explorateur Windows l'entend, mais indique plutôt les différents types de structures possibles pour le contenu des fichiers.
XIII-A-1. Fichiers texte▲
Les fichiers texte sont certainement les fichiers les plus simples à comprendre et
à utiliser en Pascal. Ces fichiers comportent du texte brut, comme vous en lisez
régulièrment dans le bloc-notes de Windows par exemple. Le texte contenu dans ce
genre de fichiers est réparti en lignes. Pour information, chaque ligne se termine,
comme dans tous les fichiers texte, par un marqueur de fin de ligne qui est
constitué d'un ou de deux caractères spéciaux : le retour chariot et éventuellement
le saut de ligne (Sous les environnements Windows, les deux caractères sont
généralements présents, contrairement aux environnements de type UNIX qui
favorisent le retour chariot seul).
Ces fichiers sont adaptés à des tâches très utiles :
- stocker du texte simple entré par l'utilisateur dans l'application par exemple
- écrire des fichiers de configuration (entre autre des fichiers INI)
- générer des fichiers lisibles par d'autres applications, comme des fichiers HTML (pages web), RTF (texte mis en page) ou CSV (texte réparti en colonnes).
Ce genre de fichier sera étudié en premier, car sa méthode d'utilisation est certainement l'une des plus simples parmi les méthodes d'accès aux fichiers.
XIII-A-2. Fichiers séquentiels▲
Les fichiers séquentiels partent sur un principe différent des fichiers texte. Leur
principe est de stocker séquentiellement (à la suite) un certain nombre d' «
enregistrements » d'un type donné, et ce de façon automatisée en ce qui concerne la
lecture et l'écriture. Tous les types de données ne peuvent pas être stockés dans
ce type de fichier : classes, pointeurs ou tableaux dynamiques, entre autres, ne
seront pas au programme.
Ce genre de fichier est surtout utilisé pour stocker une liste d'éléments de type
enregistrement (record) : à condition de n'avoir que des sous-éléments admis par le
type de fichier séquentiel, il sera possible de lire et d'écrire avec une facilité
déconcertante des enregistrements depuis les fichiers séquentiels.
Leur facilité d'utilisation avec les enregistrement est leur point fort, par
contre, leur principale faiblesse est de ne procurrer aucune liberté concernant ce
qui est concrètement écrit dans les fichiers, ou de ne pas pouvoir utiliser de
pointeurs ou de tableaux dynamiques, souvent très utiles.
XIII-A-3. Fichiers binaires▲
Ces fichiers sont aussi nommés "fichier non typé" dans l'aide de Delphi, on
prefèrera ici la dénomination générale de "fichier binaire". Ce dernier genre de
fichier est en fait un genre universel, car tous les types de fichiers, sans
exception, peuvent être créés avec ce genre de fichier : vous êtes libres à 100% du
contenu du fichier, ce qui vous permet d'élaborer une structure personnelle qui
peut être très évoluée. Mais cela a un prix : vous n'avez aucune des facilités
offertes en lecture/écriture par les fichiers texte ou les fichiers
séquentiels.
Ce genre de fichier est très souvent utilisé, car il n'est pas rare qu'on ait
besoin d'élaborer sa propre structure de fichier, pour stocker des données non
supportées par les fichiers séquentiels par exemple. Imaginez un enregistrement
comportant un tableau dynamique de pointeurs vers des données. Le type de fichier
séquentiel ne peut pas convenir ici : vous devrez effectuer manuellement les
écritures et les lectures, mais c'est à ce prix que vous êtes libres du contenu des
fichiers que vous manipulerez.
XIII-B. Manipulation des fichiers texte▲
Nous commençons comme promis par les fichiers texte. C'est le type le plus adapté pour débuter car il est très simple de vérifier les manipulations. Pour cela, il suffit d'ouvrir le fichier créé pendant la manipulation dans un éditeur de texte pour afficher son contenu. Il est à noter qu'il existe une période d'ombre entre l'ouverture et la fermeture d'un fichier, pendant laquelle le fichier ne peut pas être affiché, car il est monopolisé par votre application. Avant de détailler plus avant les moyens de tester vos résultats, voyons comment on accède à ces fichiers.
XIII-B-1. Ouverture et fermeture d'un fichier texte▲
Note aux programmeurs Turbo Pascal :
Les fichiers texte, déjà utilisables dans Turbo Pascal, sont exploités de
manière très similaire sous Delphi. La seule différence notable est que le
type "Text" est remplacé par "TextFile". La procédure d'assignation "Assign"
est remplacée par "AssignFile", et la procédure "Close" est remplacée par
"CloseFile". "Reset", "Rewrite" et "Append" sont conservées.
Vous verrez par contre dans les autres paragraphes que Delphi apporte de
nouvelles méthodes plus modernes pour l'accès aux fichiers comme l'utilisation
des flux.
Le langage Pascal Objet a sa manière bien à lui de manipuler les fichiers en général. Cette méthode, qui date de Turbo Pascal, est toujours employée sous Delphi, car elle a fait ses preuves. Un fichier texte sous Delphi se manipule par l'intermédiaire d'une variable de type "TextFile". La manipulation d'un fichier passe par 3 étapes obligatoires : 2 avant l'utilisation, et une après. Voici la déclaration de la variable fichier :
var
FichTest: TextFile;
La première étape, avant utilisation, est l'étape d'assignation. Elle consiste à
associer à la variable-fichier le nom du fichier que nous voulons manipuler. Cette
assignation se fait par l'appel d'une procédure très simple nommée "AssignFile" qui
admet deux paramètres. Le premier est la variable-fichier, le second est le nom du
fichier que vous désirez manipuler. Noter que si vous voulez lire le contenu du
fichier, il est bien évident que ce fichier doit exister.
Voici l'instruction qui assigne le fichier « c:\test.txt » à la variable-fichier
"FichTest" déclarée ci-dessus (le nom du fichier est transmis dans une chaîne de
caractères) :
AssignFile(FichTest, 'c:\test.txt');La deuxième étape consiste à ouvrir le fichier. Cette ouverture peut se faire suivant trois modes différents suivant ce qu'on a besoin de faire pendant que le fichier est ouvert. La méthode qu'on emploie pour ouvrir le fichier détermine ce mode d'ouverture. Les trois modes possibles sont la lecture seule (écriture impossible), l'écriture seule (lecture impossible), soit simplement l'ajout du texte à la fin du fichier (ajout seul). Notez qu'il n'est pas possible de pouvoir lire et écrire à la fois dans un fichier texte.
- Si on souhaite lire, il faut utiliser la procédure Reset. Si le fichier n'existe pas, attendez-vous à une erreur de la part de votre application. L'écriture n'est pas possible avec ce mode d'ouverture.
- Si on souhaite écrire, il faut utiliser la procédure Rewrite. Si le fichier existe, il sera écrasé. La lecture n'est pas possible avec ce mode d'ouverture.
- Si on souhaite juste ajouter du texte dans un fichier texte, il faut l'ouvrir en utilisant la procédure Append. Cette procédure ouvre le fichier et permet d'y écrire seulement. Ce que vous y écrirez sera ajouté à la fin du fichier.
Ces trois procédures s'utilisent de la même manière : on l'appelle en donnant comme unique paramètre la variable-fichier à ouvrir. Voici l'instruction qui commande l'ouverture du fichier c:\test.txt en lecture seule :
Reset(FichTest);Pour ouvrir le même fichier en écriture seule, il suffirait de substituer "Rewrite" à "Reset". Venons-en tout de suite à la troisième étape obligatoire : la fermeture du fichier. Cette fois-ci, c'est plus simple, car la procédure "CloseFile" (qui accepte un seul paramètre de type variable-fichier) ferme un fichier ouvert indifférement avec "Reset", "Rewrite" ou "Append". Voici l'instruction qui ferme le fichier (qui doit avoir été ouvert, sous peine d'erreur dans le cas contraire).
CloseFile(FichTest);Voici donc une procédure qui ouvre un fichier en lecture seule et le ferme aussitôt. Pour changer un peu des procédures associées aux événements, cette procédure est indépendante d'une quelconque fiche et accepte un paramètre qui est le fichier à ouvrir.
procedure OuvrirFichier(Fich: string);
var
FichTest: TextFile;
begin
AssignFile(FichTest, Fich);
Reset(FichTest);
{ lecture possible dans le fichier ici }
CloseFile(FichTest);
end;Pour tester cette procédure, créez un fichier texte ou trouvez-en un qui existe, puis appelez la procédure en donnant l'emplacement du fichier en tant que chaîne de caractères. Par exemple :
procedure TForm1.Button1Click(Sender: TObject);
begin
OuvrirFichier('c:\bootlog.txt');
end;Il est possible d'améliorer nettement cette procédure d'ouverture, notamment en contrôlant l'existence du fichier avant son ouverture, car un fichier inexistant provoquerait une erreur génante qu'il est possible d'éviter facilement. On teste l'existence d'un fichier grâce à la fonction FileExists. Cette fonction admet en unique paramètre le nom du fichier. Le résultat de la fonction est un booléen qui indique l'existence du fichier (True si le fichier existe, False dans le cas contraire). Voici la nouvelle procédure, améliorée par l'utilisation de FileExists.
procedure OuvrirFichier(Fich: string);
var
FichTest: TextFile;
begin
if not FileExists(Fich) then exit;
AssignFile(FichTest, Fich);
Reset(FichTest);
{ lecture possible dans le fichier ici }
CloseFile(FichTest);
end;Comme vous le voyez, l'ajout est fort simple, puisque l'appel de "exit" dans le cas où le fichier n'existerait pas évite la tentative d'ouverture en sortant directement de la procédure. Venons-en à la lecture.
XIII-B-2. Lecture depuis un fichier texte▲
Avant de se lancer tête baissée dans la lecture du contenu d'un fichier texte, il
faut apprendre quelques règles sur les mécanismes de lecture en Pascal. La lecture
se fait au choix par la procédure Read ou Readln ("READ LiNe", "lire ligne" en
anglais). La procédure Readln est la plus simple à utiliser car elle permet de lire
une ligne entière d'un fichier (je rappelle qu'un fichier texte est découpé en
lignes). La procédure Read, quant à elle, permet de lire de différentes manières :
caractère par caractère, ou petit morceau par petit morceau. Cette dernière
technique est à éviter car elle prend plus de temps que la lecture ligne par ligne,
et tout ce que permet la procédure Read peut être réalisé sur le texte lu au lieu
d'être réalisé sur le texte à lire. La lecture ligne par ligne sera donc la seule
étudiée ici.
Lorsqu'on ouvre un fichier texte, la « position » dans ce fichier est fixée à son
début. La « position » d'un fichier détermine à quel endroit aura lieu la prochaine
opération sur ce fichier. Pour lire une ligne d'un fichier, on utilise donc Readln.
Readln est une procédure très spéciale dans le sens où son nombre de paramètres est
a priori indéterminé. Le premier paramètre est la variable-fichier dans laquelle on
désire lire. Les paramètres suivants sont des variables permettant de stocker ce
qui a été lu. Dans la pratique, on se limite très souvent à une seule variable de
type chaîne. Voici l'instruction qui lit une ligne du fichier associé à la
variable-fichier TestFile et qui la stocke dans la variable tmpS de type
string :
Readln(FichTest, tmpS);
Il va de soi que pour que cette instruction fonctionne, il faut que le fichier soit
ouvert. Readln lit une ligne depuis la « position » en cours dans le fichier,
jusqu'aux caractères de fin de ligne (ceux-ci sont éliminés), puis fixe la nouvelle
« position » au début de la ligne suivante (sous réserve qu'elle existe, nous
allons parler de l'autre cas un peu plus bas). L'appel suivant à Readln lira la
ligne suivante du fichier, et ainsi de suite jusqu'à ce qu'il n'y ait plus de ligne
après la position dans le fichier, c'est-à-dire lorsqu'on a atteint la fin du
fichier. Pour tester cette condition, on doit faire appel à une fonction nommée Eof
("End Of File", "Fin de fichier" en anglais). Cette fonction accepte en unique
paramètre une variable-fichier et renvoie un booléen qui indique si la position de
fichier est la fin de ce dernier, c'est-à-dire que lorsque Eof renvoie True, il n'y
a plus de ligne à lire dans le fichier.
La plupart du temps, lorsqu'on lit l'ensemble des lignes d'un fichier texte, il
faut utiliser une boucle while. Cette boucle permet de lire les lignes une
par une et de tester à chaque fois si la fin du fichier est atteinte. Voici un
exemple d'une telle boucle while :
while not Eof(FichTest) do
Readln(FichTest, tmpS);La boucle ci-dessus lit un fichier ligne par ligne jusqu'à la fin du fichier. Lorsque celle-ci est atteinte, Eof devient vrai et la condition de continuation de la boucle n'est plus respectée, et la lecture s'arrète donc d'elle-même. Voici notre procédure OuvrirFichier encore améliorée. Elle lit maintenant l'intégralité du fichier transmis :
procedure OuvrirFichier(Fich: string);
var
FichTest: TextFile;
tmpS: string;
begin
if not FileExists(Fich) then exit;
AssignFile(FichTest, Fich);
Reset(FichTest);
while not Eof(FichTest) do
Readln(FichTest, tmpS);
CloseFile(FichTest);
end;
Il serait tout de même intéressant de faire quelque chose de tout ce texte que l'on
lit dans le fichier. Le plus simple est d'écrire tout ce texte dans un mémo. Placez
donc un bouton btTest et un mémo meFich sur une fiche fmPrinc. L'ajout de lignes
dans un mémo ayant déjà été étudié, nous ne réexpliqueront pas comme on fait. Pour
donner un peu de piquant à cet exemple, nous allons nous intéresser d'un peu plus
près au fichier étudié : BOOTLOG.TXT. Ce fichier, qui devrait exister à la racine
de votre disque dur, résume ce qui s'est passé durant le dernier démarrage anormal
de Windows. Ce fichier est un peu illisible par un humain, nous allons donc filtrer
les lignes qui indiquent un problème. Ces lignes comportent pour la plupart la
chaîne 'Fail' ('échouer' en anglais). Nous allons examiner chaque ligne et ne
l'ajouter au mémo que lorsque la ligne contient 'Fail'.
Pour cela, il nous faudra la fonction Pos. Cette chaîne permet de rechercher une
sous-chaîne dans une chaîne. Si la sous-chaîne est trouvée, la fonction renvoie la
position du premier caractère de la sous-chaîne dans la chaîne (par exemple si on
cherche 'our' dans 'bonjour tout le monde', le résultat sera 5, soit le numéro du
premier caractère de 'our' : o. Cette procédure recherche une sous-chaîne exacte.
Si on recherche 'Our' dans 'bonjour tout le monde', la fonction Pos renverra 0,
indiquant par là que la sous-chaîne n'existe pas dans la chaîne. Pour rechercher
sans s'occuper des minuscules/majuscules, l'idée est de faire la recherche dans des
chaînes que l'on aura préalablement mise en majuscules.
Pour mettre une chaîne en majuscules, il suffit de la transmettre à la fonction
UpperCase, qui renvoie la chaîne mise en majuscules. Voici donc la recherche de
'Fail' dans la chaîne lue, à savoir tmpS :
Pos('FAIL', UpperCase(tmpS))Pour savoir si la ligne doit être ajoutée, il suffira de comparer le résultat de Pos à 0 et d'ajouter lorsque Pos sera strictement supérieur à 0. Voici la procédure LectureFichier qui fait la lecture complète, le filtrage et l'ajout dans le mémo :
procedure OuvrirFichier(Fich: string);
var
FichTest: TextFile;
tmpS: string;
begin
if not FileExists(Fich) then exit;
AssignFile(FichTest, Fich);
Reset(FichTest);
fmPrinc.meFich.Lines.Clear;
while not Eof(FichTest) do
begin
Readln(FichTest, tmpS);
if Pos('FAIL', Uppercase(tmpS)) < 0 then
fmPrinc.meFich.Lines.Add(tmpS);
end;
CloseFile(FichTest);
end;Voilà qui conclue ce petit paragraphe consacré à la lecture dans un fichier texte. Plutôt que de vous donner sèchement la procédure Readln, j'ai préféré vous démontrer une utilisation concrète, ce qui je pense est un bien meilleur choix.
XIII-B-3. Ecriture dans un fichier texte▲
L'écriture dans un fichier texte s'effectue également ligne par ligne grâce à la
procédure Writeln, ou morceau par morceau avec la procédure Write. Contrairement à
la lecture où l'utilisation de Read est à déconseiller, l'utilisation de Write est
ici tout à fait possible, même si les temps d'écriture sont à prendre en
considération : écrire un gros fichier ligne par ligne est plus rapide qu'en
écrivant chaque ligne en plusieurs fois.
La procédure Writeln s'utilise comme Readln, mis à part qu'elle effectue une
écriture à la place d'une lecture. L'écriture se fait à la position actuelle, qui
est définie au début du fichier lors de son ouverture par "Rewrite", et à la fin
par "Append". Writeln ajoute la chaîne transmise sur la ligne actuelle et insère
les caractères de changement de ligne, passant la position dans le fichier à la
ligne suivante. Ainsi, pour écrire tout un fichier, il suffira d'écrire ligne par
ligne en appelant autant de fois Writeln qu'il sera nécessaire.
Voici une procédure qui ouvre un fichier "c:\test.txt" en tant que texte, et qui
écrit deux lignes dans ce fichier. Après l'execution de la procédure, vous pourrez
contrôler le résultat en ouvrant ce fichier dans le bloc-notes par exemple. Si vous
venez à changer le nom du fichier, méfiez-vous car l'écriture ne teste pas
l'existence du fichier et vous pouvez donc écraser par mégarde un ficbier
important. La même remarque reste valable pour chacun des fichiers que vous écrirez.
procedure TestEcriture(Fich: string);
var
F: TextFile;
begin
AssignFile(F, Fich);
Rewrite(F);
Writeln(F, 'ceci est votre premier fichier texte');
Writeln(F, 'comme vous le constatez, rien de difficile ici');
CloseFile(F);
end;
Dans l'exemple ci-dessus, le fichier texte est ouvert en écriture seule par
Rewrite, puis deux écritures successives d'une ligne à chaque fois sont effectuées.
Le fichier est ensuite normalement refermé. L'écriture, comme vous le constatez,
est beaucoup plus simple que la lecture puisqu'on a pas à se soucier de la fin du
fichier.
Voici pour conclure ce très court paragraphe un exercice typique, mais assez
instructif. Contrairement à beaucoup d'exercices donnés jusqu'ici, vous êtes
laissés très libres et vous vous sentirez peut-être un peu perdus. Pour vous
rassurer, sachez que vous avez toutes les connaissances nécessaires à la
réalisation de cet exercice, et qu'il est indispensable pour vous de pouvoir
résoudre cet exercice sans aide. Comme d'habitude, vous pourrez cependant accèder à
des indications et à un corrigé détaillé en fin de résolution.
Exercice 1 : (voir les
indications
et le corrigé)
Le but de cet exercice est de vous faire manipuler en même temps la lecture et
l'écriture, et non plus les deux chacun de leur coté. L'exercice idéal pour cela
est de réaliser une copie d'un fichier texte. Le but de l'exercice est donc
l'écriture d'une fonction de copie dont voici la déclaration :
function CopyFichTexte(Src, Dest: string): boolean;
Cette fonction, qui ne sera utilisable qu'avec les fichiers texte, copiera le
contenu du fichier texte dont le chemin est Src dans un nouveau fichier texte dont
le chemin sera Dest. La fonction renverra faux si le fichier source n'existe pas ou
si le fichier destination existe déjà (ce qui vous évitera d'écraser par accident
un fichier important). Dans les autres cas, la fonction renverra vrai pour indiquer
que la copie est effectuée. Notez que vous êtes libres de la méthode à adopter pour
effectuer vos tests, mais que vous devez en faire un minimum.
Dans un deuxième temps, écrire une fonction similaire mais nommée CopyFichTexteDemi
qui n'écrit qu'une ligne sur deux (en commencant par la première) du fichier source
dans le fichier destination.
Indication : utilisez une variable entière qui stockera le numéro de ligne qui vient d'être lu. L'écriture dépendra de la valeur de cette variable (notez qu'un nombre est impair lorsque le reste de sa division entière par deux est 1)
Bon courage !
XIII-B-4. Utilisation des fichiers texte par les composants▲
Certains composants, dont le but avoué est la manipulation du texte, permettent
également d'utiliser des fichiers texte. Ces composants proposent chacun deux
méthodes : une pour lire un fichier texte et qui fait que le composant utilise ce
texte, et une pour écrire le texte manipulé par le composant dans un fichier texte.
La méthode de lecture s'appelle généralement LoadFromFile et accepte en paramètre
le nom d'un fichier existant (une erreur est signalée si le fichier n'existe pas).
Quand à la méthode d'écriture, elle est appelée SaveToFile et accepte également le
nom d'un fichier qui est écrasé au besoin.
Ce genre de fonctionnalité très pratique pour sauver et charger facilement un texte
est gérée par la classe "TStrings". "TStrings" est l'ancêtre immédiat de la classe
"TStringList" que vous connaissez déjà, et est utilisé par de nombreux composants
pour gérer de façon interne une liste de chaînes (n'utilisez pas vous-même
"TStrings" mais "TStringList" pour gérer une liste de chaînes, sauf si vous savez
vraiment ce que vous faites). Parmi les composants qui utilisent des objets de
classe "TStrings", on peut citer ceux de classe "TMemo" : la propriété "Lines" des
composants Mémo, que nous disions jusqu'à présent de type « objet » sans préciser
davantage est en fait de type "TStrings".
La classe "TStrings", seule à être étudiée ici, définit donc les deux méthodes
LoadFromFile et SaveToFile. Pour preuve, placez un bouton "btCharg" et un mémo
"meAffich" sur une fiche "fmPrinc" et utilisez le code ci-dessous :
procedure TfmPrinc.btChargClick(Sender: TObject);
begin
meAffich.Lines.LoadFromFile('c:\bootlog.txt');
end;
Cette simple instruction appelle la méthode LoadFromFile de la propriété objet
Lines (de type TStrings) du mémo meAffich. Le paramètre est une chaîne de
caractères donnant l'emplacement du fichier à charger dans le mémo.
Si vous voulez maintenant permettre de sauver le contenu du mémo, vous pouvez créer
un bouton "btSauve" et utiliser le code suivant (toujours dans la procédure
associée à l'événement OnClick : c'est tellement habituel que je ne le préciserai
plus) :
procedure TfmPrinc.btSauveClick(Sender: TObject);
begin
meAffich.Lines.SaveToFile('c:\test.txt');
end;
Cette instruction permet de sauver le contenu du mémo dans le fichier
'c:\test.txt'. Dans l'avenir, je vous expliquerai comment afficher une des boites
de dialogue (ouvrir, enregistrer, enregistrer sous) de Windows et comment
configurer ces boites de dialogue. Vous pourrez alors permettre à l'utilisateur
d'ouvrir un fichier de son choix ou d'enregistrer avec le nom qu'il choisira.
Ceci termine la section consacrée aux fichiers texte. Bien que très utiles, ces
fichiers ne sont pas très souvent utilisés car ils sont tout simplement limités au
texte seul. Dans la section suivante, nous allons étudier les fichiers séquentiels,
qui sont adaptés à certains cas où l'on souhaite stocker une collection d'éléments
de même type.
XIII-C. Manipulation des fichiers séquentiels▲
XIII-C-1. Présentation▲
Les fichiers séquentiels sont une autre catégorie de fichiers qu'il est parfois
très intéressant d'utiliser, quoique de moins en moins dans les versions
successives de Delphi. Contrairement aux fichiers texte dont le but avoué est le
stockage de texte seul, les fichiers séquentiels sont destinés à stocker un nombre
quelconque de données du même type, à condition que le type soit acceptable.
Prenons par exemple le type de donnée suivant, qui ne devrait pas vous poser de
problème particulier :
type
TPersonne = record
Nom,
Prenom: string;
Age: word;
Homme: boolean; { vrai: homme, faux: femme }
end;
L'objectif de ce type enregistrement est bien entendu de stocker les paramètre
relatifs à une personne dans un répertoire par exemple. Imaginons maintenant que
vous utilisez ce type pour créer un petit carnet d'adresses, vous aimeriez
probablement proposer à vos utilisateurs l'enregistrement de leur carnet, sans quoi
votre application ne serait pas vraiment intéressants. L'enregistrement de telles
données, bien que techniquement possible en passant par un fichier texte, serait
pénible avec ces derniers. La solution réside dans l'utilisation d'un fichier
séquentiel, puisque ce dernier genre a été conçu spécifiquement pour répondre à ce
genre de besoin du programmeur.
Un fichier séquentiel se définit en utilisant un type Pascal Objet qui repose sur
un type plus fondamental qui désigne le type des éléments stockés dans ce fichier.
Ce type s'écrit ainsi :
file of type_de_donneeIl est possible de déclarer des variables de ce type ou d'écrire un type dédié. type_de_donnee est le type des données qui seront stockées dans le fichier. Dans notre exemple, nous allons ajouter un type "fichier de personnes" :
TPersFich = file of TPersonne;
Il suffira ensuite de déclarer une variable de type TPersFich pour pouvoir
manipuler un fichier séquentiel. Nous verrons également comment lire et écrire des
éléments de type TPersonne dans un tel fichier.
Mais ce qui nous importe à présent, c'est le message d'erreur que vous allez
recevoir si vous entrez le code présenté ci-dessus dans Delphi : il semble que
Delphi digère difficilement ce code, et ce pour une raison qui ne saute pas
forcément aux yeux : le type TPersonne contient des données non acceptables dans un
fichier séquentiel. Le coupable est le type "string" utilisé depuis Delphi 4. Ce
type, qui permet désormais de manipuler des chaînes de plus de 255 caractères
(contrairement aux anciennes versions de Delphi qui étaient limitées à 255
caractères pour le type string), n'est pas compatible avec les fichiers séquentiels
car la taille d'une variable de type string est dynamique (susceptible de
changer), ce qui n'est pas toléré dans le cadre des fichiers séquentiels. Pour
utiliser des chaînes de caractères avec des fichiers séquentiels, il faudra soit
fixer une longueur inférieure ou égale à 255 caractères pour la chaîne (en
utilisant le type string[n]) ou utiliser l'ancien type "string" utilisé dans
Delphi 3, qui a été rebaptisé "shortstring" ("chaîne courte" en anglais) (notez que
cela équivaut à utiliser le type string[255].
Voici donc notre type TPersonne revu et corrigé :
type
TPersonne = record
Nom,
Prenom: string[100];
Age: word;
Homme: boolean; { vrai: homme, faux: femme }
end;
TPersFich = file of TPersonne;
Encore une précision technique : la taille du fichier sera proportionnelle aux
tailles des variables qui y seront placées. Les chaînes de 255 caractères, bien
qu'autorisant plus de caractères, gâcheront beaucoup d'espace disque. Songez qu'en
mettant 100 au lieu de 255 dans le type ci-dessus, on économise 155 x 2 = 310
octets par élément stocké. Sur un fichier de 100 éléments, ce qui est assez peu, on
atteint déjà 31000 octets, ce qui est peut-être négligeable sur un disque dur, mais
qui doit tout de même être pris en considération.
Avant de passer aux opérations de lecture/écriture sur les fichiers séquentiels,
nous allons rapidement voir comment ouvrir et fermer ces fichiers.
XIII-C-2. Ouverture et fermeture d'un fichier séquentiel▲
Tout comme les fichiers texte, les fichiers séquentiels doivent être ouverts et
fermés respectivement avant et après leur utilisation. L'étape initialise qui
consiste à associer un nom de fichier à une variable qui désigne le fichier est
elle aussi au menu. La bonne nouvelle, cependant, est que mis à part la déclaration
des types fichiers séquentiels différente de celle des fichiers texte, les trois
opérations d'assignation, lecture et écriture sont identiques entre les deux types
de fichiers.
Les utilisations et les effets de Reset et de Rewrite sont cependant légèrement
modifiés avec les fichiers séquentiels. Au niveau de l'utilisation, Reset doit être
utilisé lorsque le fichier existe, et Rewrite lorsqu'il n'existe pas. L'effet
produit par ces deux commandes est identique pour les fichiers séquentiels : on
peut lire et écrire à la fois dans un fichier séquentiel ouvert. Voici une
procédure qui manipule un fichier de personnes : le fichier est ouvert avec Reset
ou Rewrite selon les cas et refermé aussitôt :
procedure ManipFichierSeq(FName: string);
var
Fichier: TPersFich;
begin
AssignFile(Fichier, FName);
if FileExists(FName) then
Reset(Fichier)
else
Rewrite(Fichier);
{ manipulation possible ici }
CloseFile(Fichier);
end;Deux choses sont à remarquer dans cette procédure. Tout d'abord, la variable "Fichier" est de type TPersFich, ce qui en fait un fichier séquentiel contenant des personnes : des éléments de type TPersonne. Ensuite, les méthodes d'ouverture et de fermeture ressemblent à s'y méprendre à ce qu'on fait avec les fichiers texte, et il faudra se méfier de cette ressemblance car "Fichier" est ouvert ici en lecture/écriture quelle que soit la méthode d'ouverture.
XIII-C-3. Lecture et écriture depuis un fichier séquentiel▲
Ce paragraphe sera en fait plus que l'étude de la lecture et de l'écriture, car le
fait que les fichier séquentiels soient ouverts en lecture/écriture offre de
nouvelles possibilités. Parmi ces possibilité, celle de se déplacer dans le fichier
et de le tronquer sont parfois des plus utiles.
La lecture dans un fichier séquentiel passe par la procédure standard Read.
L'écriture, elle se fait par Write. Hors de question ici d'utiliser Readln et
Writeln car les fichiers séquentiels ne sont pas organisés en lignes mais en
enregistrements. Voyons tout d'abord l'écriture :
procedure ManipFichierSeq(FName: string);
var
Fichier: TPersFich;
begin
AssignFile(Fichier, FName);
if FileExists(FName) then
Reset(Fichier)
else
Rewrite(Fichier);
Pers.Nom := 'DUPONT';
Pers.Prenom := 'Jean';
Pers.Age := 39;
Pers.Homme := True;
Write(Fichier, Pers);
Pers.Nom := 'DUPONT';
Pers.Prenom := 'Marie';
Pers.Age := 37;
Pers.Homme := False;
Write(Fichier, Pers);
CloseFile(Fichier);
end;Cette procédure écrit deux éléments de type TPersonne dans le fichier représenté par la variable "Fichier". Vous voyez qu'après avoir rempli un élément de type TPersonne, on le transmet directement en paramètre de la procédure Write. Testez cette procédure en l'appelant lors d'un clic sur un bouton (un simple appel de ManipFichierSeq avec un nom de fichier inexistant en paramètre suffit, mais vous devenez trop fort pour que je vous fasse désormais l'affront de vous donner le code source), et allez ensuite examiner la taille du fichier résultant : vous devriez avoir un fichier de 412 octets (ou une taille très proche). Pour mettre en évidence une faiblesse de notre test, mettez la deuxième opération d'écriture ainsi que les 4 affectations précédentes en commentaires.
procedure ManipFichierSeq(FName: string);
var
Fichier: TPersFich;
begin
AssignFile(Fichier, FName);
if FileExists(FName) then
Reset(Fichier)
else
Rewrite(Fichier);
Pers.Nom := 'DUPONT';
Pers.Prenom := 'Jean';
Pers.Age := 39;
Pers.Homme := True;
Write(Fichier, Pers);
{ Pers.Nom := 'DUPONT';
Pers.Prenom := 'Marie';
Pers.Age := 37;
Pers.Homme := False;
Write(Fichier, Pers); }
CloseFile(Fichier);
end;
Relancez la procédure. Retournez voir la taille du fichier : 412 octets alors que
vous n'écrivez plus qu'une fois au lieu de deux ? Es-ce bien normal ? La réponse
est bien entendu non. En fait, lorsque vous ouvrez un fichier séquentiel existant,
il faut savoir que on contenu n'est pas effacé : vous vous contentez d'écraser les
parties que vous écrivez dans le fichier. Si vous n'écrivez pas autant d'éléments
qu'il en contenait auparavant, les derniers éléments restent inchangés dans le
fichier.
Pour résoudre cet indélicat problème, il suffit de faire appel à la procédure
Truncate. Cette procédure, qui accepte en paramètre une variable fichier
séquentiel, tronque le fichier à partir de la position en cours dans le fichier.
Cette position, qui correspond à une position comptée en enregistrements, est
déterminée par la dernière opération effectuée sur le fichier :
- Après l'ouverture, la position est le début du fichier, soit la position 0.
- Chaque lecture et écriture passe la position actuelle après l'enregistrement lu ou écrit, ce qui a pour effet d'augmenter la position de 1.
- Il est aussi possible de fixer la position actuelle en faisant appel à Seek. Seek accepte un premier paramètre de type fichier et un second qui est la position à atteindre. Si cette position n'existe pas, une erreur se produira à coup sûr.
Voici notre procédure améliorée par un appel à Truncate :
procedure ManipFichierSeq(FName: string);
var
Fichier: TPersFich;
begin
AssignFile(Fichier, FName);
if FileExists(FName) then
Reset(Fichier)
else
Rewrite(Fichier);
Seek(Fichier, 0);
Truncate(Fichier);
Pers.Nom := 'DUPONT';
Pers.Prenom := 'Jean';
Pers.Age := 39;
Pers.Homme := True;
Write(Fichier, Pers);
Pers.Nom := 'DUPONT';
Pers.Prenom := 'Marie';
Pers.Age := 37;
Pers.Homme := False;
Write(Fichier, Pers);
CloseFile(Fichier);
end;Ici, l'appel de Seek est inutile, il n'est fait que pour vous démontrer cette possibilité. Le simple appel de Truncate après l'ouverture permet de tronquer entièrement le fichier. les écritures se font ensuite en ajoutant des éléments au fichier et non plus seulement en les remplacant. Lorsque vous n'aurez aucune intention de lire le contenu d'un fichier séquentiel, fixez la position dans ce fichier à 0 :
Seek(Fichier, 0);
et tronquez le fichier : vous aurez ainsi l'assurance d'écrire sans patauger dans
d'anciennes données parasites. Une autre solution est de lancer Truncate après la
dernière écriture, pour vider ce qui peut rester d'indésirable dans le fichier qui
vient d'être écrit. Vous pourrez ensuite le fermer en étant sûr que seul ce que
vous venez d'y mettre y sera écrit.
La lecture dans un fichier séquentiel se fait sur le même principe que pour les
fichiers texte : on lit à partir d'une position de départ et ce jusqu'à être rendu
à la fin du fichier. Relancez une dernière fois la procédure qui écrit les deux
enregistrements, puis effacez les affectations et les écritures. Nous allons
effectuer une lecture séquentielle du fichier que vous venez d'écrire,
c'est-à-dire que nous allons lire les éléments un par un jusqu'à la fin du fichier.
Pour cela, une boucle while est tout indiquée, avec la même condition que
pour les fichiers texte. A chaque itération, on lira un élément en affichant le
résultat de la lecture dans un message. Voici :
procedure ManipFichierSeq(FName: string);
var
Fichier: TPersFich;
Pers: TPersonne;
begin
AssignFile(Fichier, FName);
if FileExists(FName) then
Reset(Fichier)
else
Rewrite(Fichier);
Seek(Fichier, 0);
while not Eof(Fichier) do
begin
Read(Fichier, Pers);
ShowMessage(Pers.Nom + ' ' + Pers.Prenom + ' (' +
IntToStr(Pers.Age) + ' ans)');
end;
CloseFile(Fichier);
end;Exercice 2 : (voir la
solution,
les commentaires et le téléchargement)
Pour manipuler un peu plus les fichiers séquentiels par vous-même, tout en ne vous
limitant pas à de simples lectures/écritures sans rien autour, je vais vous
proposer un gros exercice d'application directe de ce qui vient d'être vu. Le
principe est de programmer une petite application (vous pouvez considèrer que c'est
un mini-projet guidé qui est proposé ici). Le principe est de générer un fichier de
personnes (prénoms, noms et âges pris au hasard). L'application pourra ensuite
effectuer un « filtrage » du fichier en affichant dans une zone de liste les
personnes du fichier dont l'âge est supérieur à une valeur donnée par
l'utilisateur. Cet exercice est assez long à réaliser, alors prévoyez un peu de
temps libre (disons au moins une heure), et résolvez les questions suivantes dans
l'ordre (vous pouvez consulter le corrigé
qui donne la solution de chaque question) :
- le programme aura avant tout besoin de générer aléatoirement des personnes (des éléments de type TPersonne). Le moyen que nous retiendrons sera l'utilisation de tableaux comprenant les noms et les prénoms. Un "random" permettra de choisir un indice au hasard dans chaque tableau, et donc un prénom et un nom indépendants. L'âge sera à générer directement avec un random, et le sexe devra être déterminé par exemple par un tableau de booléens fixés en fonction des prénoms. Créez donc la fonction GenerePersonneAlea sans paramètres et qui renvoit un résultat aléatoire de type TPersonne.
- Ecrivez maintenant la procédure "GenereFichierSeq" qui génére le fichier séquentiel. Cette procédure acceptera en paramètre le nombre de personnes à mettre dans le fichier. La procédure se permettra exceptionnellement d'écraser un éventuel fichier existant. Pour nous mettre d'accord, le fichier sera nommé 'c:\test.txt' (ce nom sera fixé par une constante). Il va de soi que les personnes écrites dans le fichier doivent être générées aléatoirement (à l'aide de la fonction écrite à la question précédente).
- Ecrivez la fonction "AffichePersone" qui permet d'afficher les renseignements sur une personne : Nom, Prenom, Age et Sexe. La fonction créera une simple chaîne de caractères qui sera renvoyée en résultat.
- Ecrivez la procédure "TraiteFichierSeq" qui permettra le traitement du fichier précédemment généré. Cette procédure acceptera deux paramètres. Le premier sera de classe "TListBox" (composant zone de liste) dans lequel seront ajoutées les personnes dont l'âge sera supérieur au deuxième paramètre (type entier). La zone de liste sera vidée en début de traitement.
-
Il est maintenant temps de créer une interface pour notre application. Inspirez-vous de la capture d'écran ci-dessous pour créer la vôtre. Les noms des composants ont été ajoutés en rouge vif.
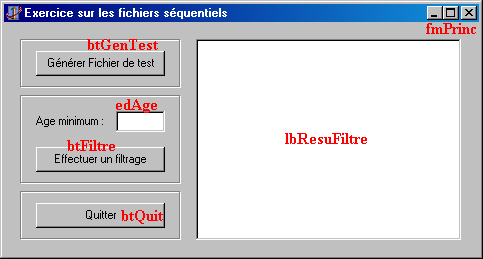
N'oubliez pas que la fenêtre ne doit pas être redimensionnable, et programmez le bouton "Quitter".
- Programmez le bouton "Générer fichier test" en appelant la procédure "GenereFichierSeq" avec 100 comme paramètre. Programmez également le bouton "Effectuer un filtrage" en appelant la procédure "TraiteFichierSeq". Le premier paramètre sera la seule zone de liste de la fiche, et le second sera obtenu depuis le texte de la zone d'édition "edAge". Le filtrage se terminera en afficbant un message qui indiquera le nombre de personnes affichées dans la liste.
Une fois toutes ces étapes réalisées, il ne vous reste plus qu'à tester le projet :
il faudra d'abord générer le fichier de test, puis donner une valeur d'âge minimum,
et tester. Vous pouvez ensuite changer de valeur d'âge ou regénérer le fichier test
pour obtenir des résultats différents.
C'est la fin de cet exercice, et aussi la fin du paragraphe consacré aux fichiers
séquentiels.
XIII-D. Fichiers binaires▲
Les fichiers binaires, dont le nom vient du fait que leur structure est
arbitrairement décidée par le programmeur, représentent la forme de fichier la plus
couramment employée, du fait de la liberté totale qui vous est laissée quant
au contenu. Contrairement aux fichiers séquentiels, les fichiers binaires ne sont
pas organisés systmatiquement en lignes ou en enregistrements, mais peuvent contenir
tout et n'importe quoi. Ainsi, vous pourrez élaborer une structure de donnée adaptée
à une application et la mettre en oeuvre grâce aux fichiers binaires.
Cette liberté de mouvement a toutefois un prix que vous finirez par accepter : les
lectures et les écritures sont plus sensibles. Il nous faudra ici faire de nombreux
tests, car de nombreux traitements faits dans notre dos avec les fichiers textes ou
séquentiels ne le sont plus avec les fichiers binaires. On peut dire que vous
rentrez de plein fouet dans la vraie programmation en utilisant les fichiers
binaires.
Dans ce paragraphe, une seule méthode d'utilisation des fichiers binaires va être
vue : l'utilisation des instructions standards de Pascal pour la gestion des
fichiers binaires. Une autre méthode qui utilise un objet de classe "TFileStream" et
qui facilite la gestion d'un fichier binaire sera vue dans un prochain chapitre.
Note aux initiés : Les méthodes présentées ici sont très perfectibles. En effet, il serait très judicieux ici d'employer des structures "try" pour vérifier que les fichiers ouverts sont systématiquement refermés. Il n'est pas ici question d'assomer le lecteur par une quirielle de détails techniques et de vérifications, mais de lui montrer une méthode de gestion d'un fichier binaire.
XIII-D-1. Présentation▲
La méthode qui consiste à gérer les fichiers binaires de façon directe est à mon
sens la méthode « brutale ». En effet, vous verrez plus tard que la classe
"TFileStream" facilite tout ce que nous allons faire ici, en apportant quelques
difficultés du fait de sa nature de classe. Cependant, cette classe masque beaucoup
d'aspects importants des accès aux fichiers que le futur programmeur ne pourra
ignorer, car si vous désirez un jour programmer en C, il vous faudra affronter des
méthodes encore plus barbares, et donc commencer en Pascal est un bon
compromis.
Nous allons débuter par un petit cours technique sur la capture et la gestion des
erreurs, et nous poursuivrons ensuite avec la gestion des fichiers binaires. Au fil
des paragraphes, quelques notions annexes vous seront présentées, car elles sont
indispensables à la bonne utilisation des fichiers binaires. S'ensuivra une
description détaillée de la lecture et de l'écriture de données de divers types
dans un fichier binaire, le tout assorti de quelques exemples.
L'écriture d'un fichier binaire ne pose en général pas de problèmes. Par contre, la
lecture impose de connaître la structure logique du fichier, c'est-à-dire que vous
devrez savoir au fur et à mesure de la lecture ce que signifie les octets que vous
lirez, car rien n'indiquera dans le fichier ce qu'ils peuvent signifier. Ainsi,
l'utilisation des fichiers binaires impose auparavant de mettre noir sur blanc la
structure du fichier qu'on va générer. Nous verrons que le plus simple moyen de
créer un fichier complexe est d'utiliser des blocs, c'est-à-dire des suites
d'octets dont le début indique ce que la suite signifie, et éventuellement la
taille de la suite. Nous verrons que cette construction peut devenir passionnante,
pour peu qu'on ait un minimum de patience et une certaine capacité d'abstraction.
XIII-D-2. Capture des erreurs d'entrée-sortie▲
Je vais me permettre un petit discours technique afin d'introduire ce qui suit.
Pascal, ou plutôt Pascal Objet est un langage compilé, c'est-à-dire que le texte
que vous écrivez passe par un logiciel spécial appelé compilateur qui fabrique un
fichier éxécutable à partir de tout votre code Pascal Objet. Ce compilateur, comme
la plupart des bons compilateurs, accepte une sorte de sous-langage qui lui est
spécifiquement destiné. Ce langage comporte des commandes incluses dans le texte
Pascal Objet, mais traitées à part. Ces commandes sont connues sous le terme de «
directives de compilation ». Ces directives indiquent qu'on souhaite un
comportement particulier de sa part lors de la compilation du code ou d'une partie
du code.
Nous allons nous intéresser ici à une seule directive de compilation, car c'est
celle qui nous permettra de détecter les erreurs provoquées par nos accès aux
fichiers. Une directive de compilation est de la forme :
{$<directive>} .C'est un commentaire, dont l'intérieur commence par un signe $, se poursuit par une directive. Dans notre cas, la directive est tout simplement I, suivi d'un + ou d'un -. Les deux directives que nous allons donc utiliser sont :
{$I+} et {$I-} .
Vous vous dites : "c'est bien beau tout ça, mais à quoi ça sert ?". La réponse a
déjà été donnée en partie précédemment : lorsque nous manipulons un fichier, chaque
commande d'ouverture (Reset et Rewrite), de déplacement (Seek), d'effacement
(Truncate), de lecture (Read), d'écriture (Write) ou de fermeture (CloseFile) est
susceptible de provoquer une erreur dite d' « entrée-sortie ». Dans le cas général,
lorsqu'une telle erreur se produit, un message d'erreur s'affiche, indiquant à
l'utilisateur la nature franchement barbare de l'erreur, dans un langage également
des plus barbares. Imaginons maintenant que nous souhaitions intercepter ces
erreurs pour y réagir nous-mêmes, et ainsi au moins empècher l'affichage du message
barbare. Pour cela, il faudra désactiver temporairement la gestion automatique des
erreurs d'entrées-sorties, et la réactiver plus tard. Dans ce laps de « temps », la
gestion des erreurs d'entrées-sorties nous incombe.
Rassurez-vous toutefois, la gestion des erreurs, à notre niveau, sera des plus
simple. Il passe par l'appel de la fonction "IOResult", qui ne peut être utilisée
que lorsque la gestion automatique des erreurs aura été temporairement désactivée
par une directive {$I-} (il faudra penser à réactiver
cette gestion automatique avec une directive {$I+}).
Lorsque la gestion automatique est désactivée, et qu'une erreur se produit, un
indicateur interne est modifié, empêchant toutes les instructions d'entrée-sortie
suivantes de s'éxexuter. Pour connaître la valeur de cet indicateur à le remettre à
0 (qui signifie « pas d'erreur »), un simple appel à "IOResult" sera nécessaire
après chaque instruction d'entrée-sortie.
Voici un exemple d'ouverture et de fermeture d'un fichier. Le procédé a été
sécurisé au maximum avec des appels à "IOResult". Nous allons expliquer le
déroulement de cette procédure ci-dessous :
function OuvrirFichier(NomFich: String): Boolean;
var
F: File;
begin { retourne vrai si tout s'est bien passé }
{$I-} { permet d'utiliser IOResult }
AssignFile(F, NomFich);
{ ouverture }
if FileExists(NomFich) then
Reset(F, 1)
else
Rewrite(F, 1);
Result := (IOResult = 0);
if not Result then exit;
{ fermeture }
CloseFile(F);
Result := (IOResult = 0);
if not Result then exit;
{$I+} { réactive la gestion automatique des erreurs }
end;
La longueur de cet extrait de code, qui ne fait pas grand chose, peut effrayer,
mais c'est à ce prix qu'on sécurise un programme qui autrement pourrait facilement
générer des erreurs. Avec la version ci-dessus, aucune erreur ne sera signalée,
quoi qu'il arrive. La procédure se termine simplement en cas d'erreur. Voyons
comment tout cela fonctionne : tout d'abord un {$I-}
permet d'utiliser IOResult. Ensuite, chaque instruction susceptible de provoquer
une erreur est suivie d'un appel à IOResult. Cet appel suffit à réinitialiser un
indicateur interne qui empêcherait autrement les autres instructions d'accès aux
fichiers de s'éxécuter. Le résultat de IOResult est comparé à 0, de sorte que si
cette comparaison est fausse, ce qui signifie qu'une erreur s'est produite, alors
la procédure se termine en passant par un {$I+} qui
réactive la gestion automatique des erreurs d'entrée-sortie (on dit aussi
simplement « erreurs d'I/O » par abus de langage)
Venons-en maintenant à la véritable description de cet exemple : vous voyez en
l'examinant que la méthode d'ouverture d'un fichier binaire (on dit également «
fichier non typé » en référence à la partie "of type" qui est absente après
le mot réservé "file" dans la déclaration de tels fichiers) ressemble beaucoup à
celle des fichiers manipulés jusqu'à présent. La seule différence notable se situe
au niveau de l'instruction d'ouverture : "Reset" ou "Rewrite", selon le cas, a
besoin d'un paramètre supplémentaire, dont la signification est assez obscure :
c'est la taille d'un enregistrement ! En fait, ces enregistrements-là n'ont rien à
voir avec ceux des fichiers séquentiels. Dans la pratique, on doit toujours
utiliser 1, ce qui signifie : "lire et écrire octet par octet".
XIII-D-3. Lecture et écriture dans un fichier binaire▲
La lecture et l'écriture dans un fichier binaire est un sport bien plus intéressant
que dans les types précédents de fichiers. En effet, il n'y a ici rien de fait pour
vous faciliter la vie. Il va donc falloir apprendre quelques notions avant de vous
lancer.
Pour lire et écrire dans un fichier binaire, on utilise les deux procédures
"Blockread" et "BlockWrite". Voici leur déclaration, ce qui vous permettra d'avoir
déjà un tout petit aperçu de leur non-convivialité (ne vous inquiètez pas si vous
ne comprenez pas tout, c'est normal à ce stade, je vais donner toutes les
explications nécessaires juste après) :
procedure BlockRead(var F: File; var Buf; Count: Integer;
var AmtTransferred: Integer);
procedure BlockWrite(var f: File; var Buf; Count: Integer;
var AmtTransferred: Integer);XIII-D-3-a. Paramètres variables▲
Avant de passer à la description, quelques explications s'imposent. Le mot var employé dans une déclaration de procédure/fonction signifie que lorsque vous donnez ce paramètre, ce que vous donnez doit être une variable, et non une constante. Par exemple, avec la procédure suivante :
procedure Increm(var A: integer);
begin
A := A + 1;
end;La procédure "Increm" a besoin d'un paramètre variable, c'est-à-dire que si vous avez une variable "V" de type integer, vous pouvez écrire l'instruction suivante, qui est correcte :
Increm(V);Par contre, l'instruction suivante serait incorrecte car le paramètre n'est pas une variable :
Increm(30);En fait, le fait de déclarer un paramètre variable fait que la procédure a non plus simplement le droit de lire la valeur du paramètre, mais a aussi le droit de modifier sa valeur : ci-dessus, la valeur du paramètre est incrémentée de 1, et toute variable que vous donnerez en paramètre à "Increm" sera donc incrémentée de 1.
Pour ceux qui veulent (presque) tout savoir :
Les paramètres non variables sont en fait donnés par valeur aux procédures,
c'est-à-dire qu'une zone mémoire temporaire est créée et la valeur du
paramètre à envoyer est copiée dans cette zone temporaire, et c'est
l'adresse de la zone temporaire qui est envoyée à la procédure. Du fait
de cette copie, toute modification laisse invariant le paramètre, ce
qui correspond bien au fait qu'il soit non variable. En revanche, dans
le cas des paramètres variables, l'adresse du paramètre est directement
envoyée à la procédure, ce qui lui permet de modifier directement le
paramètre puisque son adresse est connue (on dit que le paramètre est
donné par adresse).
Dans la mesure du possible, et par précaution, les paramètres variables
doivent être employés avec parcimonie, car ils sont souvent responsables
d'effets de bords. Cependant, ils sont très intéressants lorsqu'une fonction
doit renvoyer plusieurs résultats : on transforme la fonction en procédure
et on rajoute les résultats en tant que paramètres variables, de sorte
que la procédure écrit ses résultats dans les paramètres, ce qui est un
peu tiré par les cheveux, mais couramment employé par les développeurs.
Il faudra simplement faire attention, dans la pratique, lorsque vous utiliserez "Blockread" ou "Blockwrite", à ce que tous les paramètres que vous leur donnerez soient variables, mis à part le troisième qui pourra être une constante.
XIII-D-3-b. Paramètres non typés▲
Une petite chose devrait vous choquer dans les déclarations de "Blockread" et
"Blockwrite" : le paramètre variable "Buf" n'a pas de type ! C'est un cas très
particulier : Buf sera en fait interprété par la procédure comme un emplacement
mémoire (un peu comme un pointeur, et le type véritable de ce que vous donnerez
comme valeur pour "Buf" n'aura absolument aucune importance : vous pourrez envoyez
absolument n'importe quoi, du moment que c'est une variable.
Dans la pratique, cette caractéristique nous permettra d'envoyer une variable de
n'importe quel type, qui contiendra les données à écrire. Ce sera très pratique
pour écrire directement des entiers et des chaînes de caractères par exemple. Nous
verrons cependant que la lecture sera un peu moins drôle.
XIII-D-3-c. Description des deux procédures de lecture et d'écriture▲
Dans les deux procédures, le premier paramètre variable devra être la variable
correspondante à un fichier binaire ouvert. Le second devra être une variable de
n'importe quel type (nous y reviendrons, rassurez-vous). Nous désignerons
désormais ce second paramètre sous le nom de "Buffer" (« Tampon » en français). Le
troisième paramètre, constant, indique pour la lecture le nombre d'octets à
prendre dans le fichier et à mettre dans le Buffer : la position dans le fichier
est avancée d'autant d'octets lus et ce nombre d'octets réellement lu est écrit
dans le quatrième paramètre variable "AmtTransferred". Pour l'écriture, ce
troisième paramètre indique le nombre d'octets à prendre dans le Buffer et à
écrire dans le fichier. La position dans le fichier est ensuite augmentée du
nombre d'octets réellement écrits, et ce nombre est écrit dans le paramètre
"AmtTransferred".
D'une manière générale, pour reprendre ce qui a été dit ci-dessus, "F" désigne un
fichier binaire, "Buf" un Buffer, "Count" le nombre d'octet qu'on désire
transferrer, et "AmtTransferred" est un paramètre résultat (dont la valeur
initiale n'a pas d'importance) dans lequel le nombre d'octets réellement
transferrés est écrit. Vous pourrez ainsi savoir si vos lectures ou vos écritures
se sont bien passées.
La lecture et l'écriture de fichiers binaires étant un art dans lequel on excelle
pas vite, nous allons décrire en détail la lecture et l'écriture des types
fondamentaux, puis nous passerons aux types élaborés tels les tableaux et les
enregistrements.
XIII-D-4. Lecture et écriture des différents types de données▲
L'ensemble de ce (trop) gros paragraphe doit être considéré comme une manipulation guidée : en effet, il est indispensable d'effectuer les manipulations proposées, sans quoi vous n'aurez pas compris grand chose à ce qui va être dit. Nous allons commencer par quelques petits compléments sur les types de données, puis voir comment lire et écrire des types de plus en plus complexes dans les fichiers binaires.
XIII-D-4-a. Compléments sur les types de données▲
Chaque type de données que vous connaissez occupe une certaine quantité d'espace
en mémoire (un nombre d'octets). Cette place, qui paraît parfois variable comme
dans le cas des tableaux dynamique, est en fait toujours fixée à un nombre
d'octets. Pour faire simple, nous ne parlerons pas de l'influence que peuvent
avoir les systèmes d'exploitation et les types d'ordinateur sur la place qu'occupe
ces types en mémoire, mais il faut savoir que les chiffres que je vais annoncer
n'ont qu'une validité restreinte à Windows 95, 98, Millenium, NT 4.x ou 2000, et
sur des architectures basées sur des processeurs Intel, Cyrix ou AMD : nous n'en
parlerons donc pas...
Il est possible de connaître l'occupation mémoire (toujours en octets) d'un type
simple en utilisant la fonction SizeOf. Cette fonction des plus étranges accepte
en paramètre non pas seulement les variables, mais aussi les types. Elle renvoie
le nombre d'octets occupés par un élément (constante, variable) de ce type ou la
taille de la variable. Par exemple, éxécutez l'instruction suivante qui donne la
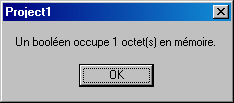
taille en octet d'un booléen :
ShowMessage('Un booléen occupe '+IntToStr(SizeOf(Boolean))+
' octet(s) en mémoire.');La réponse devrait être :
Maintenant, déclarez le type suivant (qui doit vous rappeler quelque chose) :
TPersonne = record
Nom,
Prenom: string[100];
Age: word;
Homme: boolean; { vrai: homme, faux: femme }
end;Exécutez maintenant l'instruction :
ShowMessage('Un élément de type TPersonne occupe '+IntToStr(SizeOf(TPersonne))+
' octet(s) en mémoire.');La réponse devrait avoisiner les 206 octets. Enfin, essayez l'instruction suivante :
ShowMessage('Un pointeur occupe '+IntToStr(SizeOf(Pointer))+
' octet(s) en mémoire.');
Cette fois, pas de doute sur la réponse : 4 octets (Quelques jolies surprises vous
attendent avec les types "String" et "TObject" par exemple) : ne vous rabâche-t-on
pas régulièrement que les systèmes actuels sont 32 bits ? Eh bien réfléchissez à
cela : 32 bits, c'est 4 octets... comme par hasard.
Si j'insiste aussi lourdement sur cette instruction, c'est non seulement parce
qu'elle permet d'entrevoir ce qu'il peut y avoir en dessous des types que vous
utilisez, là où personne n'aime vraiment mettre les mains, mais surtout évidemment
parce que les valeurs renvoyées par SizeOf vont énormément nous servir pour les
lectures/écritures dans les fichiers binaires.
L'autre sujet que je souhaite aborder ici, et qui est en rapport étroit avec le
précédent, concerne les chaînes de caractères. Pour ces dernières, les lectures et
les écritures vont être quelque peu pénibles, car si l'écriture ne posera pas
vraiment de soucis, en prenant des précautions, la lecture nous posera une
difficulté que j'expliquerai et que nous contournerons facilement grâce à l'emploi
de la fonction "Length". Cette fonction accepte une chaîne en paramètre et renvoie
sa vraie longueur en caractères (et non pas la place qui lui est réservée en
mémoire). Par exemple, dans l'exemple suivant, la réponse sera 6 pour la longueur
et 51 pour la taille :
procedure TForm1.Button1Click(Sender: TObject);
type
Str50 = String[50];
var
S: Str50;
begin
S := 'coucou';
ShowMessage('La longueur de S est '+IntToStr(length(S)));
ShowMessage('La taille de Str50 est '+IntToStr(SizeOf(Str50))+' octet(s).'); end;
Vous voyez qu'il serait inutile d'écrire 51 octets dans un fichier alors que 6
suffiraient en théorie (en pratique, il en faudra 7, j'expliquerai pourquoi).
Entre 51 et 7, il y a une petite différence, qui devient énorme si on envisage
d'écrire 10000 chaînes dans le fichier. "Length" et "SizeOf" nous servirons donc
conjointement.
Nous voilà armés pour débuter les lectures/écriture. Pour donner un peu de piment
aux sections suivantes, un problème tout à fait réel que vous affronterez tôt ou
tard va être étudié : l'écriture et la lecture d'un fichier d'options. L'usage
d'un tel procédé est évidemment utilisé pour sauvegarder les options d'un
logiciel. Courage et en selle.
XIII-D-4-b. Préliminaires▲
Avant de nous lancer tête baissée dans la lecture et l'écriture, il nous faut
réfléchir un minimum à l'ouverture et à la fermeture de nos fichiers : ce sera
toujours la même suite d'instructions, ce qui fait qu'on peut écrire deux
fonctions qui seront utilisées pour réaliser l'ouverture et la fermeture d'un
fichier. Ces fonctions éviterons par la suite d'avoir à répéter un grand nombre
d'instruction : ce serait pénible pour votre serviteur (en l'occurence moi), et
aurait tendance à vous perdre dans un flot de code source.
Ces deux fonctions vont utiliser un paramètre variable F de type File. En effet,
les deux fonctions devront manipuler F pour l'ouvrir ou pour le fermer. Ainsi, il
suffira de déclarer une variable fichier, et de la transmettre à l'une des deux
fonctions pour que l'ouverture et la fermeture se fasse avec toutes les
vérifications qui s'imposent. Le résultat de chaque fonction renseignera sur le
succés de l'opération.
Sans plus vous faire languir, voici les deux fonctions en question, qui sont
largement inspirées de la procédure "OuvrirFichier" présentée ci-dessus
("OuvrirFichier" est d'ailleurs transformée en fonction et ne fait plus que
l'ouverture) :
function OuvrirFichier(var F: File; NomFich: String): boolean;
begin { retourne vrai si l'ouverture s'est bien passé }
{$I-}
AssignFile(F, NomFich);
{ ouverture }
if FileExists(NomFich) then
Reset(F, 1)
else
Rewrite(F, 1);
Result := (IOResult = 0);
if not Result then exit;
{ vidage du fichier }
Seek(F, 0);
{$I+}
end;
function FermeFichier(var F: File): boolean;
begin { retourne vrai si la fermeture s'est bien passé }
{$I-}
{ fermeture }
CloseFile(F);
Result := (IOResult = 0);
{$I+}
if not Result then exit;
end;Désormais, lorsque nous disposerons d'une variable "F" de type "File", OuvrirFichier(F, nom de fichier) tentera d'ouvrir le fichier indiqué et renverra vrai si l'ouverture s'est bien passée. De même, FermerFichier(F) tentera de fermer F et renverra vrai si la fermeture s'est bien passée.
XIII-D-4-c. Types simples : entiers, réels et booléens▲
Les types simples comme les entiers, les réels et les booléens sont les plus
simples à lire et à écrire. Admettons que nous ayons à écrire un fichier qui fasse
une sauvegarde d'une liste d'options d'un logiciel. Pour simplifier, ces options
seront dans un premier temps uniquement des booléens et des nombres. Les options
consistent pour l'instant en deux cases à cocher : si la première est cochée, une
valeur entière est donnée par l'utilisateur, sinon, cette valeur est ignorée. La
deuxième case à cocher permet de saisir une valeur non entière cette fois. Cette
valeur est également ignorée si la case n'est pas cochée. La signification
concrête de ces paramètres nous importe peu, car notre travail consiste ici à
permettre la lecture et l'écriture de ces options.
Afin de représenter facilement ces données, nous allons créer un type
enregistrement, qui ne sera en aucun utilisé pour générer un fichier séquentiel :
ce serait une très mauvaise idée qui, bien qu'encore réalisable ici, deviendra
irréalisable très bientôt.
TOptions = record
Opt1, Opt2: Boolean;
Choix1: Integer;
Choix2: Real;
end;Commencez par déclarer la variable et la constante suivante à la fin de l'interface de l'unité principale du projet (je vais expliquer leur utilité ci-dessous) :
const
OptsFichier = 'c:\test.dat';
var
FOpts: File;Nous allons écrire deux fonctions ("LireOptions" et "EcrireOptions") qui lironr et écrirons respectivement les options dans un fichier dont le nom est connu à l'avance. Commençons par "EcrireOptions" : voici le squelette de cette fonction. La fonction renvoie un booléen qui indique si les options ont pu être écrites. Le seul paramètre de la fonction permet de spécifier les valeurs à écrire dans le fichier. Le code ci-dessous réalise l'ouverture et la fermeture du fichier.
function LireOptions(var Opts: TOptions): Boolean;
begin
{ on ne mettra Result à vrai qu'à la fin, si tout va bien }
Result := false;
if not OuvrirFichier(FOpts, OptsFichier) then exit;
{ effacement initial du fichier }
{$I-}
Truncate(FOpts);
if IOResult <> 0 then exit;
{$I+}
{ lecture ici }
Result := FermeFichier(FOpts);
end;
Comme vous pouvez le constater, la fonction renvoie le résultat de FermeFichier,
tout simplement parce que toutes les autres opérations feront quitter la fonction
en renvoyant False. Ainsi, si la dernière opération réussit, c'est que tout a
réussi, sinon, on sait que quelque chose n'a pas marché, sans savoir quoi.
La structure du fichier d'options sera la suivante : si l'option 1 vaut vrai, la
valeur entière est écrite dans le fichier, et pas dans le cas contraire. De même,
la valeur réelle n'est écrite dans le fichier que si l'option 2 vaut vrai. Cette
structure pourrait se noter ainsi (cette notation n'a rien d'officiel, elle est
inventée pour la circonstance :
Opt1: Boolean
{
Vrai: Choix1: Integer
Faux:
}
Opt2: Boolean
{
Vrai: Choix2: Real
Faux:
}
la lecture devra se faire entre deux directives {$I-} et {$I+} pour capturer au
fur et à mesure les éventuelles erreurs. Voici la première instruction, celle qui
écrit "Opt1" :
BlockWrite(FOpts, Opts.Opt1, SizeOf(Opts.Opt1), nbTrans);
Cette instruction mérite quelques explications, puisque c'est la première fois
qu'on utilise "Blockwrite". Le premier paramètre est le fichier dans lequel on
souhaite écrire. Ce fichier sera ouvert car sinon cette instruction n'est pas
atteinte. Le second paramètre donne le "Buffer", c'est-à-dire la donnée à écrire.
Le troisième paramètre donne le nombre d'octets à écrire. Etant donné que la
donnée est de type booléen, on donne la taille d'un booléen, et donc la taille de
Opts1 en octets. Le quatrième paramètre est une variable qui devra être déclarée
de type Integer et qui reçoit le nombre d'octets réellement écrits dans le
fichier.
Cette instruction devra être immédiatement suivie d'un test pour vérifier ce qui
s'est passé. "IOResult" doit être appelée et comparée à 0, et nbTrans doit aussi
être vérifié pour savoir si le nombre correct d'octets a été écrit. Ceci est fait
par l'instruction suivante à laquelle il faudra vous habituer :
if (IOResult <> 0) or (nbTrans <> SizeOf(Boolean)) then exit;Concrètement, si la procédure continue de s'éxécuter après ces deux instructions, il y a de fortes chances pour que "Opt1" ait été écrit dans le fichier. La suite dépend de cette valeur de "Opt1" : nous allons effectuer l'écriture de "Choix1", mais dans une boucle if qui permettra de n'éxécuter cette écriture que si "Opt1" est vrai. Voici le bloc complet, où seule l'instruction qui contient "Blockwrite" est intéressante :
if Opts.Opt1 then
begin
{ écriture de choix1 }
BlockWrite(FOpts, Opts.Choix1, SizeOf(Opts.Choix1), nbTrans);
if (IOResult <> 0) or (nbTrans <> SizeOf(Opts.Choix1)) then exit;
end;
Comme vous le voyez, on a simplement substitué "Opts.Choix1" à "Opts.Opt1". Les
deux instructions sont presque les mêmes et sont toujours du style : « écriture -
vérification ».
La suite de l'écriture ressemble à s'y méprendre à ce qui est donné ci-dessus,
voici donc la fonction complète :
function EcrireOptions(Opts: TOptions): Boolean;
var
nbTrans: Integer;
begin
{ on ne mettra Result à vrai qu'à la fin, si tout va bien }
Result := false;
if not OuvrirFichier(FOpts, OptsFichier) then exit;
{ effacement initial du fichier }
{$I-}
Truncate(FOpts);
if IOResult <> 0 then exit;
{ écriture de Opt1 }
BlockWrite(FOpts, Opts.Opt1, SizeOf(Opts.Opt1), nbTrans);
if (IOResult <> 0) or (nbTrans <> SizeOf(Opts.Opt1)) then exit;
if Opts.Opt1 then
begin
{ écriture de Choix1 }
BlockWrite(FOpts, Opts.Choix1, SizeOf(Opts.Choix1), nbTrans);
if (IOResult < 0) or (nbTrans <> SizeOf(Opts.Choix1)) then exit;
end;
{ écriture de Opt2 }
BlockWrite(FOpts, Opts.Opt2, SizeOf(Opts.Opt2), nbTrans);
if (IOResult <> 0) or (nbTrans <> SizeOf(Opts.Opt2)) then exit;
if Opts.Opt2 then
begin
{ écriture de Choix2 }
BlockWrite(FOpts, Opts.Choix2, SizeOf(Opts.Choix2), nbTrans);
if (IOResult <> 0) or (nbTrans <> SizeOf(Opts.Choix2)) then exit;
end;
{$I+}
Result := FermeFichier(FOpts);
end;Maintenant que vous avez vu la version longue, nous allons voir comment raccourcir cette encombrante fonction. En effet, vous remarquez que nous répétons 4 fois deux instructions (une écriture et un test) avec à chaque fois assez peu de variations. Il est possible de faire une fonction qui fasse cette double tâche d'écriture et de vérification, et qui renverrait un booléen renseignant sur le succés de l'écriture. Voici cette fonction :
function EcrireElem(var F: File; var Elem; nbOctets: Integer): Boolean;
var
nbTrans: Integer;
begin
{$I-}
BlockWrite(F, Elem, nbOctets, nbTrans);
Result := (IOResult = 0) and (nbTrans = nbOctets);
{$I+}
end;
"EcrireElem accepte trois paramètres : le premier, variable, est le fichier dans
lequel on doit écrire. Le second, également variable, est la donnée à écrire. Le
troisième, comme dans "BlockWrite", est le nombre d'octets à écrire. Cette
fonction va considérablement nous simplifier la tâche, car les deux instructions
d'écriture-vérification vont se transformer en quelque chose du genre :
if not EcrireElem(FOpts, variable, SizeOf(variable)) then exit;
Dans notre procédure, nous gagnerons ainsi 4 lignes et surtout nous gagnerons en
lisibilité. Nous pouvons faire encore mieux en utilisant un bloc with qui
permettra d'éviter les références à "Opts". Enfin, toutes les opérations sur les
fichiers étant réalisées à l'extérieur de la fonction "EcrireOptions", on peut
retirer les directives {$I-} et {$I+}. On pourra enfin retirer la variable "nbTrans". Voici
la fonction nouvelle formule :
function EcrireOptions(Opts: TOptions): Boolean;
begin
{ on ne mettra Result à vrai qu'à la fin, si tout va bien }
Result := false;
if not OuvrirFichier(FOpts, OptsFichier) then exit;
{ effacement initial du fichier }
{$I-}
Truncate(FOpts);
if IOResult <> 0 then exit;
{$I+}
with Opts do
begin
{ écriture de Opt1 }
if not EcrireElem(FOpts, Opt1, SizeOf(Opt1)) then exit;
if Opt1 then
{ écriture de Choix1 }
if not EcrireElem(FOpts, Choix1, SizeOf(Choix1)) then exit;
{ écriture de Opt2 }
if not EcrireElem(FOpts, Opt2, SizeOf(Opt2)) then exit;
if Opt1 then
{ écriture de Choix1 }
if not EcrireElem(FOpts, Choix2, SizeOf(Choix2)) then exit;
end;
Result := FermeFichier(FOpts);
end;Passons maintenant aux tests. Nous allons simplement déclarer une variable de type TOptions et la remplir de données factices. Enfin, nous lancerons l'écriture de ces données dans un fichier. Vous pourrez contrôler la bonne écriture du fichier en utilisant un éditeur héxadécimal tel qu'UltraEdit ou Hex WorkShop. Voici la procédure a utiliser pour effectuer le test :
procedure TForm1.Button1Click(Sender: TObject);
var
OptTest: TOptions;
begin
with OptTest do
begin
Opt1 := True;
Choix1 := 16;
Opt2 := False;
{ Choix2 non fixé }
end;
EcrireOptions(OptTest);
end;
Cette procédure donne une valeur arbitraire à certains champs de "OptTest" et
lance l'écriture. Le fichier destination est fixé, je le rappelle, par une
constante nommée "OptsFichier". A la fin de l'éxécution de cette procédure, le
contenu héxadécimal du fichier devrait être :
01 10 00 00 00 00
Je ne m'engagerai pas sur le terrain glissant de la description détaillée de ces
octets, mais sachez que si vous avez ce qui est présenté ci-dessus, votre fichier
est correctement écrit. Rien ne vous empèche ensuite de modifier "OptTest" pour
voir ce que cela donne dans le fichier généré (le nombre d'octets pourra alors
être différent).
Maintenant que l'écriture est faite, il nous reste encore à programmer la lecture
du fichier. Cette lecture se fait sur le modèle de l'écriture : lorsqu'on testait
la valeur d'une variable avant d'écrire, il faudra ici tester la valeur de la même
variable (qui aura été lue auparavant) pour savoir si une lecture du ou des
éléments optionnels est à réaliser. La lecture dans un fichier séquentiel se fait
avec "BlockRead", qui s'utilise a peu près comme "BlockWrite". Le début de la
fonction "LireOptions" ayant été donné plus haut, nous allons directement nous
attaquer à la lecture.
Comme pour l'écriture, il est avantageux pour les éléments simples d'écrire une
petite fonction annexe "LireElem" qui effectuera les détails de la lecture. Depuis
"LireOptions", il nous suffira de faire quelques appels à LireElem et le tour sera
joué. Voici donc ce qu'on pourrait utiliser comme fonction "LireElem" :
function LireElem(var F: File; var Elem; nbOctets: Integer): Boolean;
var
nbTrans: Integer;
begin
{$I-}
BlockRead(F, Elem, nbOctets, nbTrans);
Result := (IOResult = 0) and (nbTrans = nbOctets);
{$I+}
end;Comme pour l'écriture, on désactive la gestion automatique des erreurs d'entrée-sortie, et on lance un "BlockRead". Un test sur "IOResult" et sur "nbTrans" est alors effectué pour savoir si la lecture s'est bien passée. Pour lire un élément dans le ficbier d'options, et à condition que ce dernier soit ouvert, il suffira alors d'utiliser "LireElem" comme on le faisait avec "EcrireElem". Voici la partie qui lit le premier booléen (comme pour la lecture, on utiliser un bloc with pour raccourcir les écritures)
with Opts do
begin
{ lecture de Opt1 }
if not LireElem(FOpts, Opt1, SizeOf(Opt1)) then exit;
{ suite de la lecture ici }
end;La suite de la lecture consiste éventuellement à lire la valeur de "Choix1", qui dépend de "Opt1". Comme cette valeur vient d'être lue, on peut s'en servir. Voici donc la suite, qui inclue la lecture de "Choix1" dans un bloc if testant la valeur de "Opt1" :
if Opt1 then
{ lecture de Choix1 }
if not LireElem(FOpts, Choix1, SizeOf(Choix1)) then exit;Vous voyez qu'en écrivant les choses dans le style ci-dessus, les écritures et les lectures se lancent d'une façon très similaire. Dans les sections suivantes, nous verrons que cela n'est pas toujours possible. Mais pour l'instant, voici la fonction "LireOptions" en entier :
function LireOptions(var Opts: TOptions): Boolean;
begin
{ on ne mettra Result à vrai qu'à la fin, si tout va bien }
Result := false;
if not OuvrirFichier(FOpts, OptsFichier) then exit;
with Opts do
begin
{ lecture de Opt1 }
if not LireElem(FOpts, Opt1, SizeOf(Opt1)) then exit;
if Opt1 then
{ lecture de Choix1 }
if not LireElem(FOpts, Choix1, SizeOf(Choix1)) then exit;
{ lecture de Opt2 }
if not LireElem(FOpts, Opt2, SizeOf(Opt2)) then exit;
if Opt2 then
{ lecture de Choix2 }
if not LireElem(FOpts, Choix2, SizeOf(Choix2)) then exit;
end;
Result := FermeFichier(FOpts);
end;Nous allons tout de suite tester cette fonction. Le principe va être de déclarer une variable de type "TOptions", d'aller lire le fichier écrit auparavant pour obtenir les valeurs des champs de la variable, puis d'afficher les résultats de la lecture. Voici la procédure effectuant le test :
procedure TForm1.Button2Click(Sender: TObject);
var
OptTest: TOptions;
begin
LireOptions(OptTest);
if OptTest.Opt1 then
ShowMessage('Opt1 vrai, Choix1 vaut ' + IntToStr(OptTest.Choix1))
else
ShowMessage('Opt1 faux');
if OptTest.Opt2 then
ShowMessage('Opt2 vrai, Choix2 vaut ' + FloatToStr(OptTest.Choix2))
else
ShowMessage('Opt2 faux');
end;
Si vous voulez concocter une petite interface, libre à vous. Pour ceux d'entre
vous que cela intéresse, le projet ci-dessous comporte non seulement tout ce qui
est écrit ci-dessus sur les types simples, et implémente une petite interface
permettant de fixer visuellement la valeur de OptTest lors de l'écriture et de
lire visuellement ces mêmes valeurs lors de la lecture. Comme la création
d'interfaces n'est pas à l'ordre du jour, je n'y reviendrai pas.
Téléchargement : BINAIRE1.ZIP(4 Ko)
XIII-D-4-d. Types énumérés▲
Les types énumérés nécessitent un traitement particulier pour être stockés dans un
fichier binaire. En effet, ces types sont une facilité offerte par Pascal Objet,
mais ils ne pourront en aucun cas être traités comme tels dans les fichiers
binaires. Bien que ces types soient en fait des entiers bien déguisés, il ne nous
appartient pas de nous appuyer sur de telles hypothèses, même si elles nous
simplifieraient la vie. L'astuce consistera donc à écrire la valeur ordinale d'un
élément de type énuméré. Lors de la lecture, il faudra retransformer cette valeur
ordinale en un élément du type énuméré correct, ce qui se fera assez
simplement.
Considérons le type énuméré et la variable suivants :
type
TTypeSupport = (tsDisq35, tsDisqueDur, tsCDRom, tsDVDRom, tsZIP);
var
SupTest: TTypeSupport;Pour ce qui est de l'écriture, il faudra passer par une variable temporaire de type "Integer" qui stockera la valeur ordinale de "SupTest". Cette valeur entière sera ensuite écrite normalement par un "BlockWrite". Voici un extrait de code qui démontre cela :
var
SupTest: TTypeSupport;
tmp, nbOct: Integer;
begin
{ ouverture et effacement ... }
tmp := Ord(SupTest);
{$I-}
BlockWrite(Fichier, tmp, SizeOf(Integer), nbOct);
if (IOResult <> 0) or (nbOct <> SizeOf(Integer)) then exit;
{$I+}
{ fermeture ... }
end;Lorsqu'on a besoin de lire un élément de type énuméré (que l'on a écrit, et donc dont on est sûr du format de stockage), il faut lire une valeur entière, qui est la valeur ordinale de l'élément à lire. Par une simple opération dite de « transtypage » (nous ne nous étendrons pas pour l'instant sur ce vaste sujet), il sera alors possible de transformer cette valeur ordinale en une valeur du type énuméré. Voici un extrait de code qui effectue une lecture correspondante à l'écriture ci-dessus.
var
SupTest: TTypeSupport;
tmp, nbOct: Integer;
begin
{ ouverture ... }
{$I-}
BlockRead(Fichier, tmp, SizeOf(Integer), nbOct);
if (IOResult <> 0) or (nbOct <> SizeOf(Integer)) then exit;
{$I+}
SupTest := TTypeSupport(tmp);
{ fermeture ... }
end;La lecture est très conventionnelle : elle s'effectue en donnant une variable de type "Integer" à la fonction "BlockRead". Vous remarquez au passage que la lecture et l'écriture manipulent exactement le même nombre d'octets. Mais l'instruction qui nous intéresse est plutôt celle-ci :
SupTest := TTypeSupport(tmp);
Sous l'apparence d'un appel de fonction, c'est une fonctionnalité très
intéressante de Pascal Objet qui est utilisée ici : le transtypage des données.
Cette instruction ne se lit pas comme un appel de fonction, mais réalise en fait
une conversion de la valeur de "tmp" en une valeur de type "TTypeSupport". Cette
valeur est alors affectée à "SupTest". Ce transtypage dit « explicite » est
obligatoire, sans quoi le compilateur vous retournerait une erreur.
Lorsqu'on parle d' « explicite », c'est qu'il existe une version « implicite ». En
effet, lorsque vous additionnez les valeurs de deux variables : une de type
"Integer" et une de type "Real" par exemple, vous écrivez simplement l'addition et
vous stockez le résultat dans une variable de type "Real" par exemple. Il faut
savoir qu'un transtypage implicite s'opèère lors de cette addition : l'entier est
converti en nombre à virgule flottante (dont la partie décimale est nulle mais non
moins existante), puis l'addition s'effectue, et enfin le résultat est
éventuellement converti dans le type de la variable à laquelle vous affectez le
résultat. Si j'ai pris le temps de vous rappelez ceci, c'est pour que vous ne vous
effrayez pas devant un transtypage du style « TTypeSupport(tmp) » qui n'a rien de
bien compliqué, à condition de penser à le faire.
XIII-D-4-e. Types chaîne de caractères▲
Les chaînes de caractères sont un morceau de choix lorsqu'il s'agit de les écrire
ou de les lire depuis un fichier binaire. En effet, il existait auparavant un seul
type de chaîne de caractère, nummé "String", limité à 255 caractères. Depuis
Delphi 3, ce type "String" désigne une nouvelle implémentation du type chaîne de
caractères, limité à (2 puissance 32) caractères, soit pratiquement pas de limite.
L'ancien type "String" est dorénavant accessible par le type "ShortString". Pour
éviter toute ambiguité, il est également possible (mais je vous le déconseille)
d'utiliser "AnsiString" à la place de "String".
Comme si deux types ne suffisaient pas, le type "String" peut, suivant les cas,
contenir des chaînes de caractères à 1 octet (les chaînes classiques), ce qui
correspond dans la plupart des cas à l'implémentation par défaut, mais ce type
peut également stocker des chaînes Unicode, c'est-à-dire des chaînes de caractères
sur 2 octets (chaque caractère est stocké sur 2 octets, ce qui donne un alphabet
de 65536 caractères au lieu de 256). Comme la deuxième implémentation n'est pas
encore très couramment employée, et qu'elle est nettement plus délicate à
manipuler, nous nous limiterons ici à la première exclusivement.
Que nous parlions de chaînes courtes ("ShortString") ou de chaînes longues
("String"), les notions suivantes sont valables :
- Chaque caractère est stocké dans 1 octet en mémoire
- Le premier caractère est le caractère n°1. Ca a peut-être l'air bête, dit comme ça, mais si S est une chaîne, S[1] est son premier caractère (si S en contient au moins 1) et S[0] ne signifie rien pour les chaînes longues, alors qu'il contient une valeur intéressante pour les chaînes courtes, ce qui nous permettra de gagner du temps.
- La fonction "Length", qui admet un paramètre de type chaîne courte ou longue, renvoie la longueur d'une chaîne.
- La procédure "SetLengrh", qui admet en premier paramètre une chaîne courte ou longue, et en second un nombre entier, fixe la longueur d'une chaîne à cette valeur entière. Cette procédure nous servira lors des lectures.
Le format de stockage d'une chaîne de caractères est assez intuitif, bien qu'il
n'ait rien d'obligatoire (vous pouvez en inventer un autre, charge à vous de le
faire fonctionner) : on écrit d'abord une valeur entière qui est le nombre
d'octets dans la chaîne, puis on écrit un octet par caractère (puisqu'on se limite
à des caractères de 1 octet).
Ainsi, pour les chaînes courtes, un octet sera suffisant pour indiquer la taille
de la chaîne, car un octet peut coder une valeur entre 0 et 255, ce qui est
précisément l'intervalle de longueur possible avec une chaîne courte. Après cet
octet initial, viendront de 0 à 255 octets (1 par caractère). Les chaînes courtes
sont particulièrement adaptées à ce traitement car elles sont stockées de manière
continue en mémoire (un bloc d'un seul tenant) en commençant par le caractère 0
qui stocke la longueur actuelle de la chaîne. En fait, ce caractère 0, de type
Char comme les autres, ne sera pas exploitable directement. Pour avoir la valeur
entière qu'il représente, il faudra au choix passer par la fonction "Ord" pour
obtenir sa valeur ordinale ou alors effectuer un transtypage vers le type "Byte"
(« Byte(S[0]) » si S est une chaîne de caractères), ou encore passer par la
fonction "Length".
En ce qui concerne les chaînes longues, une valeur sur 4 octets (un "Integer")
sera nécessaire pour stocker la longueur. Les caractères seront écrits tout comme
ci-dessus après cette valeur. le nouveau type "String" n'offre pas, comme
l'anciern, de facilité pour obtenir la longueur. Il faudra donc en passer par
"Length".
Voici ci-dessous un exemple démontrant l'écriture d'une chaîne courte (la fonction
d'écriture et la procédure de test. Les deux fonctions OuvrirFichier et
FermeFichier sont celles du paragraphe précédent) :
function EcrireChaineC(S: ShortString): boolean;
var
nbOct: Integer;
begin
Result := false;
{ ouverture }
if not OuvrirFichier(FOpts, OptsFichier) then exit;
{$I-}
{ effacement initial }
Seek(FOpts, 0);
Truncate(FOpts);
if IOResult <> 0 then exit;
{ écriture de la chaîne }
BlockWrite(FOpts, S[0], Byte(S[0]) + 1, nbOct);
if (IOResult <> 0) or (Byte(S[0]) + 1 <> nbOct) then exit;
{$I+}
{ fermeture }
Result := FermeFichier(FOpts);
end;
procedure TForm1.Button1Click(Sender: TObject);
var
S: ShortString;
begin
S := 'Bonjour à tous !';
EcrireChaineC(S);
end;
L'appel a "BlockWrite" est la seule instruction qui nous intéresse ici : le
premier paramètre est toujours le fichier dans lequel on écrit. Le second est plus
original : ici, on ne transmet pas une variable, opération qui consisterait à
donner l'adresse du premier octet de cette variable (vous vous souvenez des
adresses, n'est-ce pas ? Sinon, retournez faire un tour ici),
mais le premier de la suite d'octets qu'on souhaite écrire dans le fichier (c'est
l'adresse de ce premier octet qui sera prise). Dans notre cas, le premier octet
stocke le nombre de caractères. Les caractères suivants étnat les caractères. Ceci
explique d'ailleurs la valeur donnée en nombre d'octets à transmettre : c'est le
nombre de caractères obtenu par un transtypage de "S[0]" en "Byte" (qui donne le
nombre de caractères) auquel on ajoute 1 pour écrire non seulement l'octet qui
donne ce nombre au début, plus les Byte(S[0]) caractères de la chaîne.
Une fois la procédure de test éxécutée, une édition héxadécimale du fichier
résultant donne :
10 42 6F 6E 6A 6F 75 72 20 E0 20 74 6F 75 73 20 21
Vous voyez que la première valeur héxadécimale est 10, c'est-à-dire 16 en décimal.
Après cette valeur, viennent 16 autres qui sont les valeurs héxadécimales des 16
caractères de la chaîne 'Bonjour à tous !'.
Venons-en à l'écriture de chaînes longues. La fonction suivante réalise cela :
function EcrireChaineL(S: String): boolean;
var
Longu, nbOct: Integer;
begin
Result := false;
{ ouverture }
if not OuvrirFichier(FOpts, OptsFichier) then exit;
{$I-}
{ effacement initial }
Seek(FOpts, 0);
Truncate(FOpts);
if IOResult < 0 then exit;
{ écriture de la chaîne }
Longu := Length(S);
BlockWrite(FOpts, Longu, SizeOf(Longu), nbOct);
if (IOResult <> 0) or (SizeOf(Longu) <> nbOct) then exit;
BlockWrite(FOpts, S[1], Longu, nbOct);
if (IOResult <> 0) or (Longu <> nbOct) then exit;
{$I+}
{ fermeture }
Result := FermeFichier(FOpts);
end;
Un listing hexadécimal du fichier résultant serait alors :
Un listing hexadécimal du fichier résultant serait alors :
10 00 00 00 42 6F 6E 6A 6F 75 72 20 E0 20 74 6F 75 73 20 21
10 00 00 00 42 6F 6E 6A 6F 75 72 20 E0 20 74 6F 75 73 20 21
Vous remarquez que les 16 dernières valeurs sont identiques à celles présentes
dans le fichier précédent, ce qui est normal puisque les mêmes caractères ont été
écrits. Ce qui change, c'est la séquence : "10 00 00 00" qui remplace "10". Cette
séquence correspond à la valeur 16, mais en 32 bits (4 octets) cette fois au lieu
des 8 bits (1 octet) l'autre fois (La valeur de 16 en héxadécimal et sur 32 bits
est 00000010, ce qui donne 10 00 00 00 dans un fichier car c'est une convention de
stocker les octets dans l'ordre inverse pour les nombres).
Voilà pour l'écriture qui est, comme vous pouvez le voir, quelque chose d'assez
simple à réaliser. La lecture est un peu plus délicate pusqu'il faut savoir quel
type de chaîne a été écrite dans le fichier, puis lire la taille de la chaîne en
spécifiant le bon nombre d'octets (1 ou 4), fixer la longueur de la chaîne,
opération souvent oubliée par les néophytes, et enfin lire autant d'octets que de
caractères.
Note : cela n'a rien à voir avec la notion dont nous sommes en train de parler, mais à partir de ce point, les codes source Pascal que vous pourrez voir sont générés automatiquement par une petite application Delphi, étant donné qu'ils commencent à s'allonger et que la conversion manuelle est assez pénible. Si vous constatez des problèmes de mise en forme ou de mise en page, n'hésitez pas à me contacter
function LireChaineC(var S: Shortstring): boolean;
var
Longu: Byte;
nbOct: Integer;
begin
Result := false;
{ ouverture }
if not OuvrirFichier(FOpts, OptsFichier) then exit;
{$I-}
Seek(FOpts, 0);
if IOResult <> 0 then exit;
{ lecture de l'octet indiquant la longueur }
BlockRead(FOpts, Longu, 1, nbOct);
if (IOResult <> 0) or (nbOct <> 1) then exit;
SetLength(S, Longu);
{ lecture des caractères }
BlockRead(FOpts, S[1], Longu, nbOct);
if (IOResult <> 0) or (nbOct <> Longu) then exit;
{$I+}
{ fermeture }
Result := FermeFichier(FOpts);
end;
La lecture se fait donc en deux temps : un élément de type "Byte" sert à lire
l'octet qui donne la longueur de la chaîne. Une fois cet octet lu avec succès, on
commence par fixer la longueur de la chaîne. Que ce soit pour une chaîne courte et
à plus forte raison pour une chaîne longue, cette étape est indispensable pour
préparer la chaîne à recevoir le bon nombre de caractères. Il ne faut pas ici
fixer un nombre trop petit car alors les caractères supplémentaires seront au
mieux perdus et provoqueront au pire un plantage de votre application et/ou de
Windows (vous avez remarqué comme Windows est un environnement stable, n'est-ce
pas ?). La lecture des caractères se base sur le nombre lu précédemment. La valeur
transmise en deuxième paramètre donne, comme précédemment pour les écritures, le
premier octet mémoire dans lequel écrire les données lues dans le fichier.
La lecture d'une chaîne longue se fait exactement de la même manière, mis à part
que la variable temporaire "Longu" doit être de type Integer. Voici la fonction
qui démontre la lecture d'une chaîne longue :
function LireChaineL(var S: string): boolean;
var
Longu,
nbOct: Integer;
begin
Result := false;
{ ouverture }
if not OuvrirFichier(FOpts, OptsFichier) then exit;
{$I-}
Seek(FOpts, 0);
if IOResult <> 0 then exit;
{ lecture de l'octet indiquant la longueur }
BlockRead(FOpts, Longu, 4, nbOct);
if (IOResult <> 0) or (nbOct <> 4) then exit;
SetLength(S, Longu);
{ lecture des caractères }
BlockRead(FOpts, S[1], Longu, nbOct);
if (IOResult <> 0) or (nbOct <> Longu) then exit;
{$I+}
{ fermeture }
Result := FermeFichier(FOpts);
end;
Et voilà le travail !
Essayez de manipuler tout cela un peu vous-même, en combinant par exemple les
chaînes courtes, les chaînes longues et d'autres éléments.
XIII-D-4-f. Autres types▲
Les types de base étant maîtrisés, les types plus élaborés ne vous poseront pas de
problème. Pour écrire un enregistrement, il suffira d'écrire ses éléments un par
un dans le fichier dans un format qui permet de relire les données sans ambiguité
(comme avec les chaînes de caractères). Pour écrire les tableaux (dynamiques ou
non), il faudra faire comme avec les chaînes : écrire dans une variable sur 1, 2
ou 4 octets le nombre d'éléments, puis écrire les éléments un par un.
En ce qui concerne les pointeurs, les écrire sur disque relève du non-sens,
puisqu'ils contiennent des adresses qui sont spécifique à l'ordinateur, à
l'utilisation de la mémoire, et également à l'humeur du système d'exploitation.
Les objets ou composants ne s'écrivent pas non plus sur disque. Si vous voulez
mémoriser certaines de leurs propriétés, il faudra connaître leur type et écrire
des valeurs de ce type dans le fichier.
XIII-D-4-g. Structures avancées dans des fichiers binaires▲
Ce que j'ai décrit dans les paragraphes précédents suffit la plupart du temps
lorsqu'on a une structure de fichier figée ou linéaire, c'est-à-dire dont les
éléments ont un ordre déterminé et un nombre d'occurences prévisibles. Par contre,
dés qu'on s'aventure dans le stockage de données complexes, les structures
linéaires deviennent insuffisantes et on doit avoir recours à d'autres structures.
Ce que j'ai expliqué dans un grand nombre de pages écran n'est qu'un petit bout de
ce qu'il est possible de faire avec les fichiers binaires.
Le but de ce paragraphe n'est pas de passer en revue les différentes structures
plus ou moins évoluées de fichiers, qui existent virtuellement en nombre infini,
mais de donner un exemple partant d'une structure bien réelle : celle du GIF.
Notre exemple sera la structure des ficbiers GIF, que vous avez certainement déjà
eu l'occasion de rencontrer : ces fichiers sont en effet omniprésents sur
l'Internet. Ces fichiers GIF ont une structure bien définie, mais aucunement
linéaire. La base du fichier comporte un petit nombre d'octets qui donnent la
"version" du fichier, c'est-à-dire une indication sur le format des données du
fichier. Ensuite, viennent un certain nombre de blocs, dont certains sont
obligatoires, dont certains rendent obligatoires certains autres, dont l'ordre
d'apparition est parfois libre, parfois arbitraire, ... bref, il n'y a pas de
structure figée.
Pour lire et écrire de tels fichiers, il faut élaborer des algorithmes parfois
complexes, qui font appel à différentes procédures ou fonctions qui s'appelent
mutuellement. Ce que j'essaie de vous dire, c'est qu'à ce niveau, il m'est
impossible de vous guider dans la lecture ou l'écriture de tels fichiers : vous
devrez essayer par vous-mêmes.
La même remarque est valable si vous avez besoin d'une structure de stockage
personnalisée : dés que vous sortez des sentiers bien balisés des fichiers texte
et des fichiers séquentiels, vous aterrissez dans le domaine complètement libre
des fichiers binaires, ou vous êtes certes maître de la structure de vos fichiers,
mais où cette liberté se paye en complexité de conception des méthodes de lecture
et d'écriture.
Si je prends le temps de vous assomer de généralités à la fin d'un aussi long
chapitre, c'est avant tout pour vous inciter à vous méfier de vous-même : il est
en effet très tentant, dés lors qu'on se sent libre de choisir la structure d'un
fichier, d'élaborer avec soin la structure d'un fichier de sauvegarde. Seulement,
il faudra alors penser au temps que vous consacrerez à l'écriture des
procédures/fonctions de lecture et d'écriture dans vos fichiers : le jeu en
vaudra-t-il la chandelle ?